

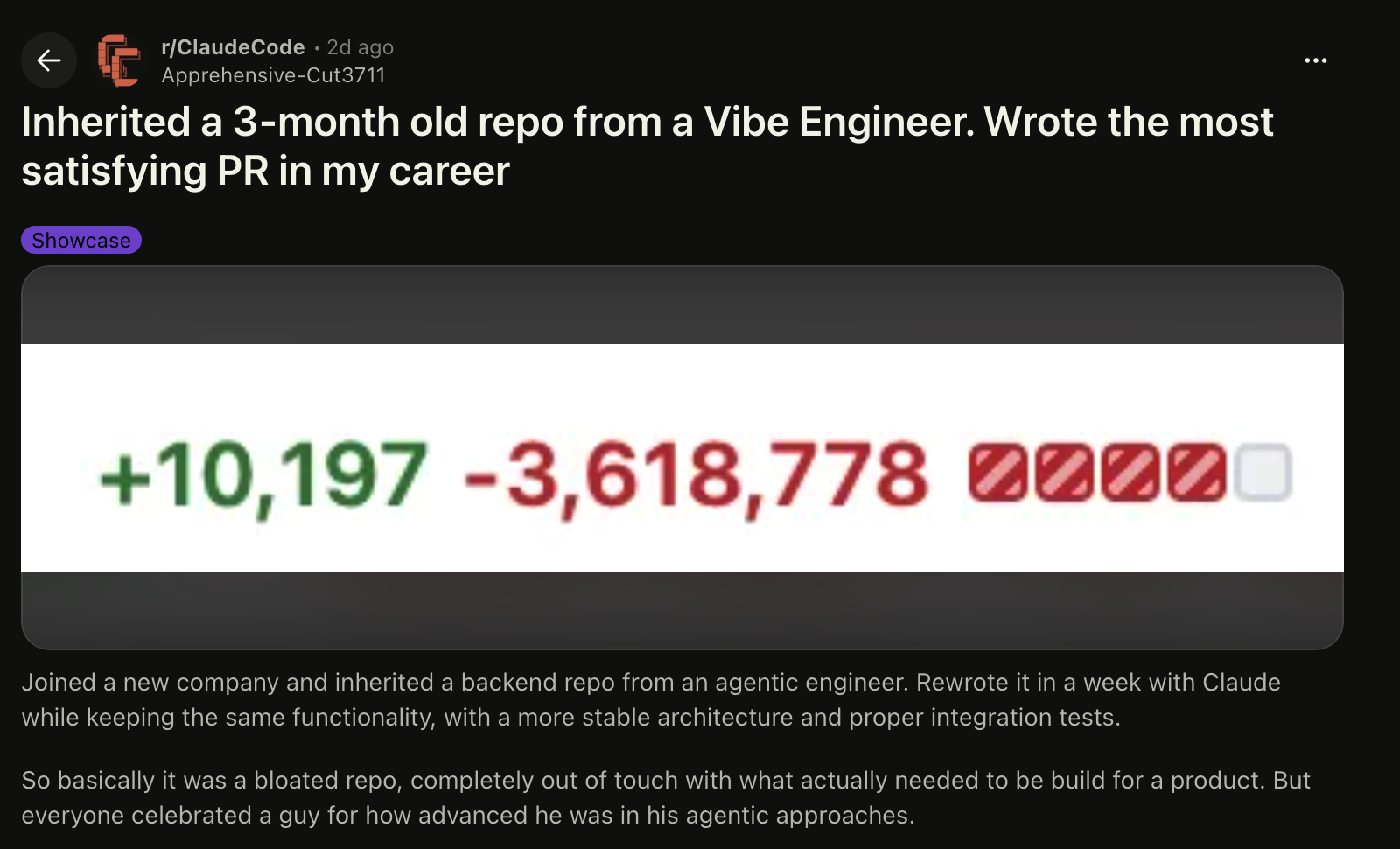
I came across a Reddit post the other day where an engineer described inheriting a three-month-old backend repo from an “agentic engineer.” The part that jumped out was not the drama. It was the size of the cleanup. The post mentions 309k lines of code, 240k lines of docs, and 1M+ lines of logs in Markdown files. Comments on the thread also reference a cleanup of around 3 million lines removed, which is the kind of number that makes your Git diff look like it escaped from a landfill.
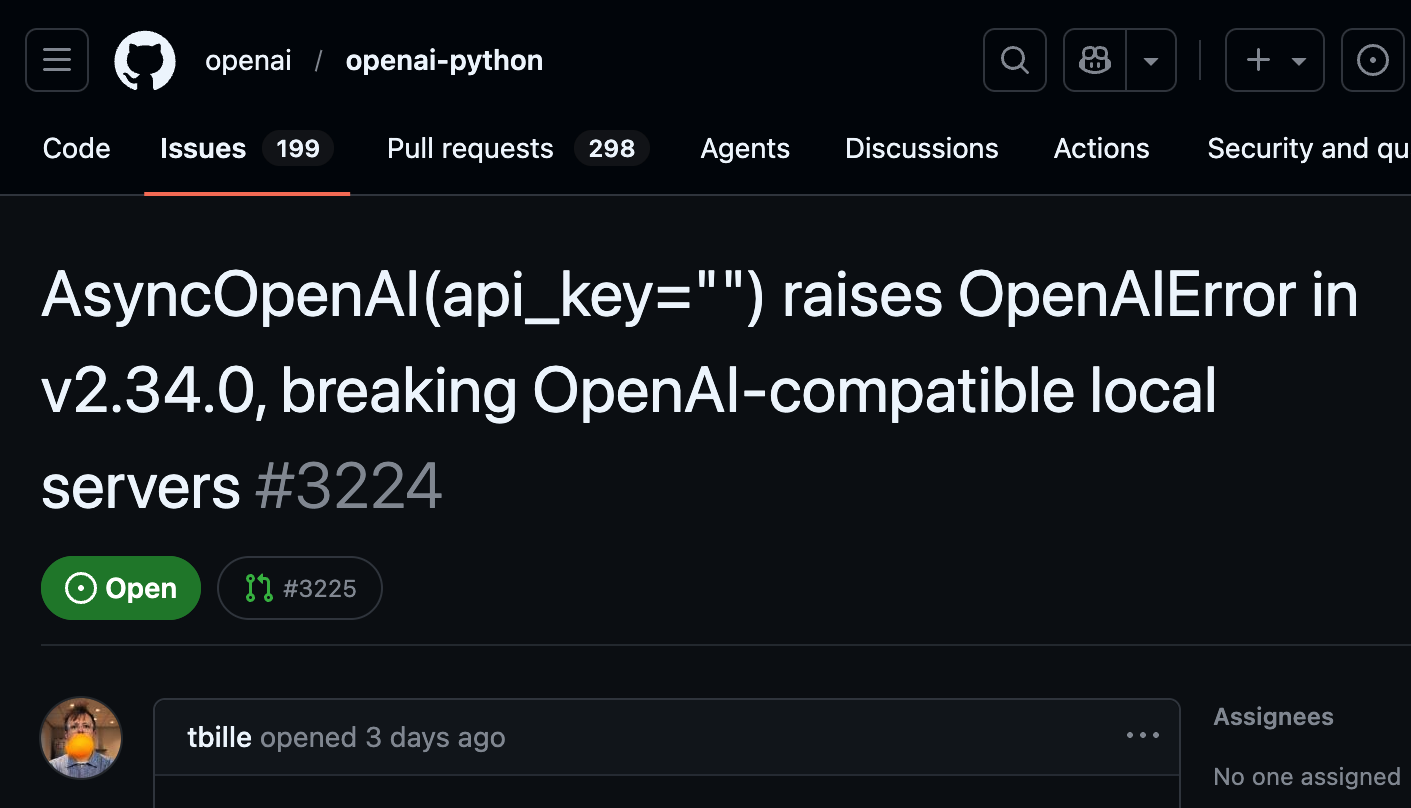
That example stuck with me because I have been seeing the same pattern show up in SDKs and APIs recently. Not always as millions of lines of dead code, but as something worse for developers: broken interfaces. A recent OpenAI Python SDK issue describes a change in v2.34.0 where AsyncOpenAI(api_key=””) started raising a missing credentials error, breaking OpenAI-compatible local servers that previously worked with an empty API key. These are not theoretical problems. These are “your app worked yesterday, and now production is holding a tiny funeral” problems.
This is what happens when AI is allowed to manage API and SDK changes without strong human control. AI coding tools can generate code quickly. They can wire things together. They can even produce useful patches. But non-trivial APIs and SDKs are not only code. They are contracts. They carry user expectations, migration paths, naming conventions, compatibility rules, and all the weird edge cases developers depend on. In this post, we’ll look at three reasons why leaning too hard on AI for API and SDK development is a bad idea. Let’s start with the first topic… AI is better at adding code than understanding the whole system.
AI is Good at Adding Code, Not a Holistic View
The Reddit example is useful because the project apparently still had the same functionality after the cleanup. That matters. The issue was not that the system needed hundreds of thousands of lines to work. The issue was that the codebase had grown into a pile of generated surface area: unused handlers, massive unintelligible docs, and logs dumped into Markdown files because, apparently, civilization needed one more way to make repos unreadable. The post mentions 220 handlers, with only about 20 actually used, and 40+ secrets, of which only 2 are needed to run the project. That is not architecture.
This is one of the core failure modes with AI coding tools. They are good at adding code. They are less reliable at deciding what should not exist. Refactoring is not only moving files around or making code look cleaner. Good refactoring requires judgment. It means understanding intent, deleting dead paths, preserving behavior, reducing surface area, and making changes without breaking the contract users depend on. That is hard because the right answer is often to write less code, not more. And AI tools, left unchecked, tend to solve uncertainty by generating more… because nothing says “engineering discipline” quite like adding another abstraction layer to explain the abstraction layer.
The bigger problem is scope. Agent memory and context windows limit how much of the system these tools can reason about at once. Even when they can scan a repo and apply memory compression, they still struggle to keep the right details active: public interfaces, older behavior, migration paths, and undocumented user dependencies. That matters a lot for SDKs. A method signature, parameter name, default value, return object, environment variable, or REST path may look small inside a diff. But for a user, that small change can break a build, block an upgrade, or force a rewrite.
This is where AI-generated changes become dangerous for API and SDK work. The tool may update one section correctly while missing another part of the codebase that depends on the old behavior. It may rename a field because the new version feels more consistent. It may “fix” a constructor, tighten validation, or normalize a response object without realizing that real users rely on the old shape. In normal application code, that might be annoying. In an SDK, that is a contract violation.
Humans Fail at Project Management
Building an SDK is not a new problem. Backward compatibility matters because developers build real systems on top of these interfaces. Once people depend on your SDK, every method name, object shape, default value, and error behavior becomes part of the user experience. Change those too often, and your SDK stops feeling like a tool. It starts feeling like a haunted dependency.
So why do we keep seeing obvious compatibility failures? There are really only a few explanations, and none of them are flattering. Either:
- The people familiar with the code are not reviewing AI-generated changes carefully enough, or
- The people now responsible for maintaining the SDK do not fully understand what counts as a breaking change
The second case is especially messy. AI has made it easier for more people to produce code, but producing code is not the same as maintaining a public interface. An SDK maintainer is not only shipping features. They are protecting users from unnecessary churn.
The even scarier part… teams that do understand breaking changes sometimes solve the problem by bumping the major version every few months. Technically, that follows semantic versioning. Practically, it creates a terrible developer experience. A major version bump should signal a meaningful shift, not a recurring tax on users because the project cannot keep its interface stable. If your SDK needs a migration guide every quarter, the problem is not only the code. The problem is product discipline.
This is where human failure matters more than AI failure. AI can propose bad changes. That is expected. It has no personal stake in whether someone’s build breaks at 2 a.m., because apparently that remains a human leisure activity. But maintainers are supposed to catch those changes. They are supposed to ask: Does this break existing users? Does this require a major version? Is there a compatibility shim? Has the old behavior been tested? Is the migration worth the pain? When that review does not happen, the SDK becomes less trustworthy. And once developers stop trusting your SDK, they start looking for another platform.
AI Doesn’t Scale Importance Well
We just looked at the maintainer problem. Now we need to look at the AI problem, because both failures feed each other. Good API and SDK maintainers understand that not all code changes have the same weight. A renamed local variable inside a private helper is not the same as a renamed argument in a public constructor. A new internal validation check is not the same as changing behavior that existing users depend on. Humans, at least the careful ones, understand the blast radius of a change because they understand the people on the other side of it.
AI does not scale that importance well. It can read a file and suggest a change. It can follow a prompt that says “do not break backward compatibility.” But that does not mean it understands compatibility in practice. Backward compatibility lives at many levels: REST URLs, auth behavior, constructor signatures, parameter names, enum values, response fields, exception types, retry behavior, pagination defaults, and even what happens when someone passes an empty string instead of None. To a model, those may look like small cleanup tasks. To users, those are contracts… and contracts are where “small cleanup” ends up as a GitHub issue.
That is why I think AI coding assistants are inherently risky for SDK work when left unchecked. They are biased toward producing a working current state rather than preserving every meaningful old state. Even if your CLAUDE.md, AGENT.md, or system prompt says “never break backward compatibility,” the tool still needs tests, review gates, API diff checks, contract tests, migration discipline, and maintainers who know what the public interfaces actually are. Without that, the AI will treat an interface like code to improve, rather than a promise to keep… and that is how an SDK slowly becomes hostile to the developers it is supposed to help.
The Full Stop Thought
AI coding tools are useful, but they are not magic project maintainers with perfect memory and taste. The three failure points are clear:
- AI is better at adding code than taking a holistic view of a system.
- Humans are still responsible for project management, review discipline, and protecting users from churn.
- AI does not scale importance well. It can treat a changed constructor, a renamed field, a stricter validation rule, or an altered response shape as a normal refactor, even when, to users, it is a broken contract.
I am not saying AI is bad for coding… and of course the tools and models are getting better everyday. AI can help generate tests, explore implementations, draft migration code, and speed up boring work. But if you maintain an API or SDK and do not have a strong grasp of the changes your AI coding assistant is proposing, you are not improving the developer experience. You are gambling with it. Once developers feel like every upgrade might break their project, they will start looking for a platform maintained by someone who understands that an SDK is not just code. It is a promise.
