I was recently at a conference where I started chatting with a computer science graduate about job hunting in the world today. We discussed the job market landscape as it exists today and all of the economic influences, disruptive technology (cough, AI, cough), and competition out there.

When I first jumped into my first professional job out of college, the world was entirely a different place. Social media was still an infant, we were rapidly approaching the dot-com bubble, and we were a few years away from (real) smartphones becoming available. In this conversation, I reflected on what challenges I faced then and wondered how I would react to the demands and problems faced in the current technology climate.
Having been on both sides of the aisle when it comes to the interview process as an interviewee and building one of the best teams as an interviewer, I thought it might be good to share the conversation I had and also expand on it a little further having had a little more time to think about it. Let’s dive into it…
How LinkedIn Connects Candidates to Employers
LinkedIn has become the go-to platform for recruiters seeking top talent, but it’s evolving beyond a simple job board. The platform has adjusted its algorithm to prioritize actively engaged candidates – those who post updates, comment on other people’s posts, and interact with their network. Simply having a profile and being logged in isn’t enough anymore. Recruiters want to connect with individuals who use the platform daily in the event an opportunity finds its way into your inbox, and, second, that you demonstrate interest and expertise in their field through their activity.
Look at this from the recruiter’s and LinkedIn’s point of view. If you are paying buckets of cash for LinkedIn Hire to find a candidate for an open position, you, as a recruiter, ideally want a response to each message sent. Also, LinkedIn doesn’t want to connect individuals to a recruiter who might not respond. This is the summary of the interaction right here… full stop. This shift means job seekers need to rethink their approach.

Staying visible requires active participation, from sharing industry insights to engaging with thought leaders. Those who embrace this shift can significantly increase their chances of being noticed and approached for opportunities. In contrast, passive candidates who only update their profiles when job hunting may find themselves overlooked. Being “active” on any job platform (especially LinkedIn) usually means you will reply to an inquiry for an open job.
AI Will Kill the Resume
The rise of AI tools has transformed the job application process, making it easier than ever for candidates to create tailored resumes that align perfectly with job descriptions. Tools like ChatGPT can generate highly customized resumes that match job listings with striking accuracy. I haven’t done this myself because I am very selective of the positions that I am seeking. Still, as someone more open to different types of work, using a prompt that mashes your resume and the job description together, I am guessing it might put you at the top of the list.

However, this has created a significant challenge for recruiters… many candidates look great on paper but lack the actual skills needed for the job. This trend has led to an increase in candidates getting through the initial screening, only to falter during technical interviews or practical assessments. I see a lot of chatter on subreddits where it’s been very difficult to land a job, let alone get a call back after the first interview. As AI-driven resume generation becomes more common, companies will need to adopt new strategies to verify a candidate’s true abilities before moving forward in the hiring process.
As someone who has helped build teams, it’s VERY time consuming hiring people. The time spent on the interview process is time spent away from doing my actual day-to-day tasks; unfortunately, that work doesn’t stop just because I am interviewing candidates. Even back then, I was very selective about the individuals who got an email for an interview.
How Do You Prove Competence?
With AI making it easier to “embellish” resumes, the challenge for employers is determining whether a candidate truly possesses the skills they claim. Just as students can use AI to complete homework without fully understanding the material, job seekers can list expertise they don’t genuinely have or may just have passing knowledge in. This presents a costly dilemma for businesses… how do they identify qualified individuals without wasting resources on lengthy interview processes?

Organizations are adopting different screening mechanisms, such as skill assessments, project-based evaluations, and real-world problem-solving tests. Conducting multiple rounds of interviews can be expensive and inefficient, so refining the process to quickly filter out candidates that may not be a good match is crucial to maintaining productivity and hiring success. I think we are in the middle of this shift right now.
Having said that, I hope this isn’t a new era of “Interview 2.0” questions because you know… all software engineers need to be able to tell you how to get 4 gallons of water using only a 3 and 5-gallon jug or to estimate the number of trees in Central Park. Although, I would rather do that than have a week-long programming assignment to prove I know how to program. Trust me, I have declined many of those because it’s like I have an infinite amount of time in my day and love doing work for free.
Public Speaking and Open Source May Hold the Answer
So what do we do about this particular problem?
To address the challenge of validating skills without extensive in-person interviews, companies/interviewers may want to turn to alternative proof of competencies, such as public speaking engagements and, for the tech world, their open-source contributions. Reviewing a candidate’s GitHub activity, technical blog posts, or recorded presentations can provide valuable insights into their expertise and problem-solving abilities.
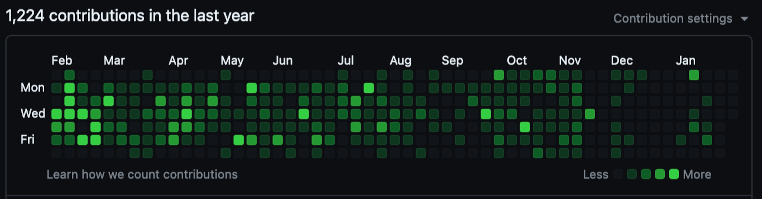
Although I never really looked at user content 7-10 years ago, I did look at GitHub and open source contributions on other platforms. With AI being able to generate code in any language these days, there is something to be said about supporting a product or an open source project. When a user/customer reports an issue, the project maintainer must triage, root cause the problem, and interact with another human being. This speaks volumes.

Similarly, public speaking appearances or videos posted on social media platforms like LinkedIn, YouTube, etc, at industry events or webinars allow recruiters to see how well candidates can articulate complex concepts. At the end of presentations, there is inevitably a Q&A session where they aren’t going to be able to use ChatGPT to answer a question live in-person. These in-person examples or recorded sessions provide a more authentic measure of skill and commitment than a polished resume ever could.
The Full Stop Thought
So, where do we go from here? We are seeing some of these changes happen in recruiting today. I have heard of interviews where a link kicks off a recorded session, and you, as the interviewer, are presented with questions to answer on video for review later. I don’t know how effective this is, but I have heard of this happening. Is this a good solution? It sounds horrible if you ask me, but change is happening.
As someone who has been on both sides of the fence, the challenges in hiring today are interesting and unique, to say the least. However, there is something to be said for verifiable contributions, like GitHub or posted videos. As someone who thinks social media has done a number on society and who only has socials for work-related purposes only, I came to one possible answer… this content can provide a window into someone’s vested interest in topics they chose and how they demonstrate understanding of that topic.
Until next time!