

By now you probably have read the blog post, ScaleIO Framework v0.3: Deploy This!, where we announced the new version of the ScaleIO Framework. (If you haven’t, I would definitely go check it out first.) In that release, a new feature called Imperative Deployment was unveiled which is the first structured method for deploying ScaleIO into your Apache Mesos cluster. In this blog post, we are going to do a deep dive for that feature and highlight some of the interesting and cool things that Imperative Deployment brings to this release.
Let’s Kick this Off
The first thing we should point out when it comes to ScaleIO is that you need a strategy when it comes to how you want to deploy it. Since ScaleIO is flexible and allows for infinite possible combinations, each one of those combinations has pros and cons. So it turns out that the marketing material that makes ScaleIO super easy to use glosses over the fact that there is actually a set of best practices that you need to adhere to get the most out of ScaleIO.
We are going to tackle various ScaleIO deployment scenarios in a series of installment blogs and our first topic will discuss environments for demos, dev/test, and smaller configurations. In this type of configuration, a fully distributed or hyper-converged deployment might be best to roll out since you are dealing with a relatively small number of systems. Demo and dev/test environments are trivial as it “just needs to work” and performance is an afterthought. So let’s take a look at a real world hyper-converged configuration. It goes without saying that you want to have at least a 3-node Mesos master quorum to tolerate failure. For the ScaleIO MDM nodes (Primary, Secondary, and TieBreaker), we will make use of the 3 nodes used for the Mesos masters. Then for the compute, we will have 16 Mesos Agent nodes configured each with a single 2TB drive. This configuration must have already been pre-created prior to deploying the ScaleIO Framework.
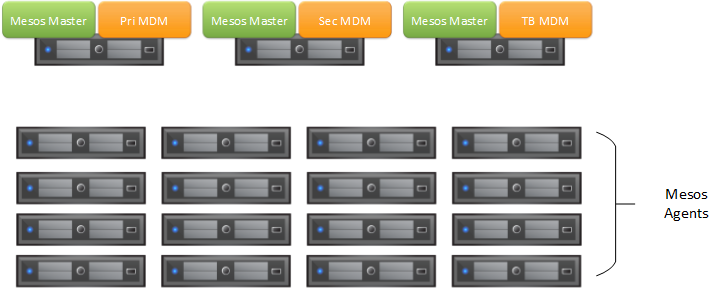
To deploy ScaleIO using the Framework’s Imperative Deployment feature, you would define similar Mesos Agent attributes as mentioned in the “Deploy This!” blog article. Before we begin, it is important to understand what the scaleio-sds and scaleio-sdc attributes really mean. The scaleio-sds represents the protection domains and storage pools that will be created on ScaleIO and which disks/devices will be contributed to that domain/pool combination. The scaleio-sdc represents the protection domains and storage pools to which that particular node will provision and consume ScaleIO volumes from. So very simply put, the difference between sds and sdc is sds is the server configuration of the disk/devices offered up to ScaleIO and sdc is the client configuration to consume volumes from ScaleIO.
The Imperative Configuration
So in the 3 Mesos Master + 3 ScaleIO MDMs and 16 Mesos Agent node configuration defined above, if you had the 2TB drives installed at /dev/xvdf for each node (can be verified using fdisk), your Mesos Agent node’s attributes would look like the block below. Note that any changes to your Mesos Agent attributes will require a restart of your Mesos Agent service before deployment of the Framework.
# cat /etc/mesos-slave/attributes/scaleio-sds-domains mydomain #cat /etc/mesos-slave/attributes/scaleio-sds-mydomain mypool # cat /etc/mesos-slave/attributes/scaleio-sds-mypool /dev/xvdf # cat /etc/mesos-slave/attributes/scaleio-sdc-domains mydomain #cat /etc/mesos-slave/attributes/scaleio-sdc-mydomain mypool
Now a few things should be noted. It might be wise to use more meaningful names than mydomain or mypool. If this was for the Quality Engineering department, maybe mydomain can be replaced with engineering and mypool with qe. The next thing is this assumes all devices are configured at /dev/xvdf but depending on your storage controller, the drive might be at /dev/xvdg for example, so replace it with the discovered or assigned value. Lastly, since REX-Ray currently only supports provisioning volumes from ScaleIO on a single protection domain and storage pool, we could omit the definition of any /etc/mesos-slave/attributes/scaleio-sdc attributes. There exists code such that the last defined scaleio-sds domain and pool are automatically used for the scaleio-sdc components. When REX-Ray implements multi-domain/pool capabilities, this code will likely be deprecated.
Finally, let’s assume that we know for certain that all the disks/devices are attached to /dev/xvdf because the initial setup was performed using your favorite DevOps tool or you are in AWS (/dev/xvdf happens default when you add your first disk), you could have deployed based on the ScaleIO Framework’s Single Global Pool method which would automatically attached all unused (ie without a filesystem) disks on the 16 Mesos Agent nodes. The default protection domain and default storage pool names can be overwritten with meaningful names using the configuration options -scaleio.protectiondomain=engineering and -scaleio.storagepool=qe. The end results of both methods in this particular case would have been identical.

This appears to be simpler than the Imperative deployment, why don’t we just use the Single Global Pool method all the time? First, keep in mind that only a single protection domain and single storage pool can be created. You may want to have more that one and in that case, you must use Imperative Deployment (Example Below). Second, if you have disks without a partition that you want to allocate for some other function like additional local storage, the Single Global Pool method will automatically consume and contribute that disk/device to ScaleIO. Warning: This includes Agent nodes to be added to the cluster for expansion! Defining these attributes for new nodes to be on-boarded to the cluster yields an explicit configuration and without these attributes, newly on-boarded nodes will contribute all disks/devices presented to that node based on the -scaleio.protectiondomain and -scaleio.storagepool configuration options.
An example of multiple StoragePools. Maybe Mesos Agent nodes 1-8 are defined like:
# cat /etc/mesos-slave/attributes/scaleio-sds-domains engineering #cat /etc/mesos-slave/attributes/scaleio-sds-engineering qe # cat /etc/mesos-slave/attributes/scaleio-sds-qe /dev/xvdf
And Mesos Agent nodes 9-16 are defined like:
# cat /etc/mesos-slave/attributes/scaleio-sds-domains engineering #cat /etc/mesos-slave/attributes/scaleio-sds-engineering development # cat /etc/mesos-slave/attributes/scaleio-sds-development /dev/xvdf
What’s next?
A piece of functionality that is currently being worked on is Fault Sets. This will allow one to specify which nodes can fail without data loss. This will naturally allow for advanced configurations for ScaleIO and happens to be the target for the next blog article in this series.
Further down the road, there are plans to work on a Declarative Deployment option which kind of sits between the simplicity of the Single Global Pool and the explicit Imperative Deployment methods. By providing more abstract constructs, your end result will yield deployment of bigger configurations without getting into the weeds of managing what devices belong to what protection domain or storage pool.
Be sure to check out the ScaleIO Framework project on GitHub and visit the {code} labs page to test drive this feature. All feedback is welcome!


