

There has been a huge push to take containers to the next level by twisting them to do much more. So much more in fact that many are starting to use them in ways that were never originally intended and even going against the founding principles of containers. The most noteworthy principle of containers being left on the designing room floor is without a doubt is being “stateless”. It is pretty evident that this trend is only accelerating… just doing a simple search of popular traditional databases in Docker Hub yields results like MySQL, MariaDB, Postgres, and OracleLinux in Docker Hub (Oracle suggests you might try running an Oracle instance in a Docker container. LAF!). Then there is all the NoSQL implementations like Elastic Search, Cassandra, MongoDB, and CouchBase just to name a few. We are going to take a look to see how we can bring these workloads into the next evolution of stateful containers using the Mesos Elastic Search Framework as a proposed model.

The problem with stateful containers today is that pretty much every implementation of a container whether its Docker, Apache Mesos, or etc has been architected with those original principles, such as being stateless, in mind. When the container goes away, anything associated with the container is gone. This obviously makes it difficult to maintain configuration or keep long term data around. Why make this tradeoff to begin with? It keeps the design simple. The problem is useful applications all have state somewhere. As a response, container implementations enabled the ability to store data on the local disks of compute nodes; thus tying workloads to a single node. However on the failure of a particular node, you could potentially lose all data on the direct attached storage. Not good for high availability, but at least there was some answer to this need.
Enter the Elastic Search Mesos Framework
This brings me to a recently submitted Pull Request to the Elastic Search (ES) Mesos Framework project on GitHub to add support for External Storage orchestration, but more importantly to enable management of those external storage resources among Mesos slave/agent nodes. Before I jump into talking about the ES Framework, I probably should quickly talk about Mesos Frameworks in general. A Mesos Framework is a way to specialize a particular workload or application. This specialization can come in the form of tuning the application to best utilize hardware, like a GPU for heavy graphics processing, on a given slave node or even distributing tasks that are scaled out to place them in different racks within a datacenter for high availability. A Framework is consists of 2 components a Scheduler and an Executor. When an resource offer is passed along to a Scheduler, the Scheduler can evaluate the offers, apply its unique view or knowledge of its particular workload, and deploy specialized tasks or applications in the form of Executors to slave/agent nodes (seen below).
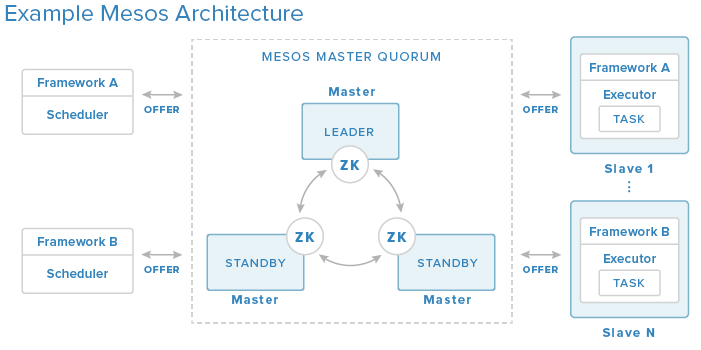
The ES Framework behaves in the same way described above. The design of the ES Scheduler and Executor have been done in such a way that both components have been implemented in Docker containers. The ES Scheduler is deployed to Marathon via Docker and by default the Scheduler will create 3 Elastic Search nodes based on a special list of criteria to meet. If the offer meets that criteria, an Elastic Search Executor in the form of a Docker container will be created on the Mesos slave/agent node representing the output for that offer. Within that Executor image holds the task which in this case is an Elastic Search node.
Deep Dive: How the External Storage Works
Let’s do a deep dive on the Pull Request and discuss why I made some of the decisions that I did. I first broke apart the OfferStrategy.java into a base class containing everything common to a “normal” Elastic Search strategy versus one that will make use of external storage. Then the OfferStrategyNormal.java retains the original functionality and behavior of the ES Scheduler which is on by default. Then I created the OfferStrategyExternalStorage.java which removes all checks for storage requirements. Since the storage used in this mode is all managed externally, the Scheduler does not need to take storage requirements into account when it looks at the criteria for deployment.
The critical piece in assigning External Volumes to Elastic Search nodes is to be able to uniquely associate a set of Volumes containing configuration and data of each elastic search node represented by /tmp/config and /data. That means we need to create, at minimum, runtime unique IDs. What do I mean runtime unique? It means that if there exists a ES node with an identifier of ID2, there exists no other node with an ID2. If an ID is freed lets say ID2 from a Mesos slave/agent node failure, we make every attempt to reuse that ID2. This identifier is defined as a task environment variable as seen in ExecutorEnvironmentalVariables.java.
addToList(ELASTICSEARCH_NODE_ID, Long.toString(lNodeId));
LOGGER.debug("Elastic Node ID: " + lNodeId);
private void addToList(String key, String value) {
envList.add(getEnvProto(key, value));
}
Why an environment variable? Because when the task and therefore the Executor is lost, the reference to the ES Node ID is freed so that when a new ES Node is created, it will replace the failed node and the ES Node ID will be recycled. How do we determine what Node ID we should be using when selecting a new or recycling a Node ID? We do this using the following function in ClusterState.java:
public long getElasticNodeId() {
List taskList = getTaskList();
//create a bitmask of all the node ids currently being used
long bitmask = 0;
for (TaskInfo info : taskList) {
LOGGER.debug("getElasticNodeId - Task:");
LOGGER.debug(info.toString());
for (Variable var : info.getExecutor().getCommand().getEnvironment().getVariablesList()) {
if (var.getName().equalsIgnoreCase(ExecutorEnvironmentalVariables.ELASTICSEARCH_NODE_ID)) {
bitmask |= 1 << Integer.parseInt(var.getValue()) - 1;
break;
}
}
}
LOGGER.debug("Bitmask: " + bitmask);
//the find out which node ids are not being used
long lNodeId = 0;
for (int i = 0; i < 31; i++) {
if ((bitmask & (1 << i)) == 0) {
lNodeId = i + 1;
LOGGER.debug("Found Free: " + lNodeId);
break;
}
}
return lNodeId;
}
We get the current running task list, find out which tasks have the environment variable set, build a bit mask, then walk the bitmask starting from the least significant bit until we have a free ID. Fairly simple. As someone who doesn’t run Elastic Search in production, it was pointed out to me this would only support 32 nodes so there is a future commit that will be done to make this generic for an unlimited number of nodes.
Let’s Do This Thing
To run this, you need to have a Mesos configuration running 0.25.0 (version supported by the ES Framework) with at least 3 slave/agent nodes, you need to have your Docker Volume Driver installed, like REX-Ray for example, you need to pre-create the volumes you plan on using based on the parameter --frameworkName (default: elasticsearch) appended with the node id and config/data (example: elasticsearch1config and elasticsearch1data), and then start the ES Scheduler with the command line parameter --externalVolumeDriver=rexray or what ever volume driver you happen to be using. You are all set! Pretty easy huh? Interested in seeing more? You can find a demo on YouTube located below.
BONUS! The Elastic Search Framework has a facility (although only recommended for very advanced users) for using the Elastic Search JAR directly on the Mesos slave/agent node and in that case, code was also added in this Pull Request to use the mesos-module-dvdi, which is a Mesos Isolator, to create and mount your external volumes. You just need to install mesos-module-dvdi and DVDCLI.
The good news is that the Pull Request has been accepted and it is currently slated for the 8.0 release of Elastic Search Framework. The bad news is the next release looks like to be version 7.2. So you are going to have to wait a little longer before you get an official release with this External Volume support. HOWEVER if you are interested in test driving the functionality, I have the Elastic Search Docker Images used for the YouTube video up on my Docker Hub page. If you want to kick the tires first hand, you can visit https://hub.docker.com/r/dvonthenen/ for images and instructions on how to get up and running. The both the Scheduler image (and the Executor image) were auto created as a result of the gradle build done for the demo.
Frameworks.NEXT
What’s up next? This was a good exercise in adding on to an existing Mesos Scheduler and Executor and the {code} team may potentially have a Framework of our own on the way. Stay tuned!
