I know that in my last blog post I said I would be talking (and probably announcing) the FaultSet functionality planned for the next release of the ScaleIO Framework. As all things in the world of technology and software, things don’t always go as planned. So today I am here to talk about some stuff relating to the Framework that will be in my speaking session entitled How Container Schedulers and Software Defined Storage will Change the Cloud at SCaLE 15x this Saturday March 4th at 3pm in Ballroom F of the Pasadena Convention Center.
![]()
This new functionality at face value seems straight forward but the implications start to open the doors to next level thought kinda stuff. Ok ok ok. I may have oversold that a little, but the idea itself is still pretty cool and I am super excited to talk about here.
Just make it happen. I don’t care how!
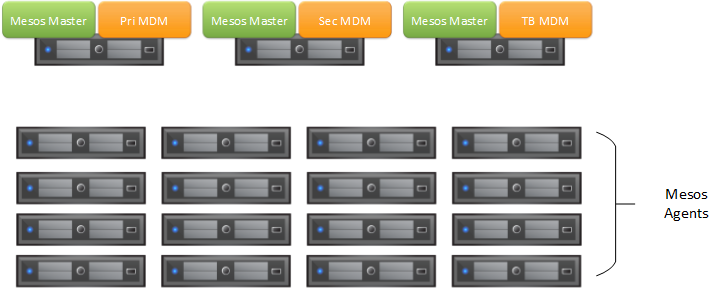
Just this week, I released the ScaleIO Framework version 0.3.1 which has a functionality preview **cough** experimental **cough** for a couple of features that I think is cool. The first feature, although not as interesting, will probably be the most useful immediately to people that want use ScaleIO but was turned off from the installation instructions… starting from a bare Mesos cluster, you can provision the entire ScaleIO storage platform in an highly available 3-node configuration from scratch and have all the storage integrations, like REX-Ray and mesos-module-dvdi, installed automatically.

In case you missed it… without having to know anything about ScaleIO, you can deploy an entirely software-based storage platform that will give your Mesos workloads the ability to persist application data seamlessly, that is globally accessible, and make your apps highly available. This abstracts the complexities of the entire storage platform and transforms it into a simple service where you can simply consume storage from. As far as any user is concerned, the storage platform natively came with Mesos and the first app you deploy can consume ScaleIO volumes from day one. If you want more details on how to make that happen, please check out the documentation.
The Sky is Falling!! Do Something?!?!
I think the second functionality preview **cough** experimental **cough** in the 0.3.1 release has perhaps the most compelling story but may be less useful in practice (at least for now). I have always been fascinated by this idea that applications, when they run into trouble, can go and fix themselves. We often call this self-remediation. In reality, that has always been a pipe dream but there is some really cool infrastructure in the form of Mesos Frameworks that make this idea a possibility.

So this second feature comes from my days as both a storage and backup user… where I get the dreaded storage array is full notification. This typically entails getting another expander shelf for your storage array (if you are lucky enough to have expansion capability), populate disks in the expansion bay, and then configure the array to accept this new raw capacity. In the age of Clouds and DevOps, anything is possible and provisioning new resource is only as far as an API call away.

The idea is that as our ScaleIO storage pool starts to approach full, we can provision more raw disks in the form of EBS volumes to contribute to the storage pool. Since we exist in the cloud or in this case AWS that is only an API call away. That is exactly idea behind this feature… to live in a world where applications can self-remediate and fix themselves. Sounds cool yea?!?! If you are interested in more information about this feature, I urge you to check out the user guide, try it out, provide input and feedback! And if you happen to be at SCaLE 15x this week, I will be doing this exact demo live! BONUS: You can watch that video demo that was performed at SCaLE here:
Where to go next…
So I hope the FaultSet functionality is just around the corner along with the support for CoreOS, or what they are now calling Container Linux, since a lot of the stuff coming out of Mesos and DC/OS is now based on that platform. Let us know if you want more surrounding Mesos and the ScaleIO Framework by hitting me up in our {code} community slack channel #mesos. Additionally, if you are in the Los Angeles area this week, I would highly recommend stopping by SCaLE 15x in Pasadena, catch some of the sessions, and stop by the {code} booth in the expo hall to continue the conversation.